
Fiesta: a Gaussian-basis GW and Bethe-Salpeter code
This is a very minimal Fiesta website. Detailed features, benchmark calculations, examples, can be found in the related papers (see Publications list).
Fiesta ad minima.
The Fiesta code implements the GW and Bethe-Salpeter formalisms using Gaussian bases and
resolution-of-the-identity techniques (RI-SVS density and RI-V Coulomb metric). Dynamical
screening contribution to the self-energy is explicitely accounted for through a contour
deformation approach. Self-consistency on the wavefunctions is implemented at the static
COHSEX level. Tamm-Dancoff approximation (TDA) or full Bethe-Salpeter
calculations can be performed. The code presently reads input Kohn-Sham eigenstates
from the Orca and
NWChem packages.
Any DFT code dumping all Kohn-Sham eigenstates (occupied/unoccupied) expressed on a Gaussian basis set can be branched rather straighforwardly onto the Fiesta code.
The Fiesta code implements continuous polarizable models (PCM) and is merged with
the Mescal Discrete Polarizable Model (DPM) [see: D'Avino et al., JCTC 2014;
Li, D'Avino et al. JPC Lett. 2016] so as to provide embedded GW and Bethe-Salpeter QM/MM formalisms.
Fiesta has now evolved into the beDeft (beyond-DFT) package, a major C++/MPI restructuration including
a newly developed analytic continuation approach [JCTC 16, 1742], cubic-scaling "space-time" RPA and GW [JCTC 17, 2383],
and a subsystem-based GW formalism.
On-going efforts to implement excited-states BSE gradients within the Z-vector formalism [JCP 159, 024116].
The Fiesta and beDeft codes have been so far shared with a few selected academic partners.
A github open-access version is under active preparation.
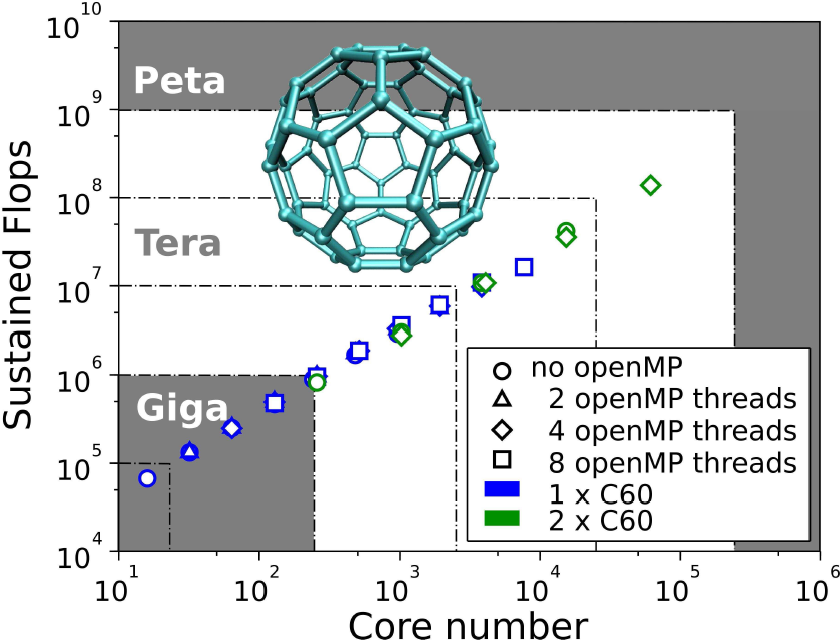
The Fiesta code is written in F90/MPI. It was initially developed having in mind to run GW/BSE
calculations for moderate size systems (~100 atoms) on a standard desk PC (e.g. 8 cores/32 Go)
with a reasonable basis (e.g. 6-311G**). If you happen to have access to larger computers, the code
has been shown to sustain excellent scaling up to several thousand cores, allowing GW/BSE
calculations on several hundred atoms with e.g. aug-cc-pvtz quality basis.
Left image: Performance of one GW iteration for one or two fullerenes (RI-SVS metric,
DZP basis). The processor grid size varies from 16 to 61440 cores. 138 TeraFlops were reached
for the largest grid (European PRACE project, Ivan Duchemin, L_sim/INAC/CEA/Grenoble).